Playground notes
The playground exercise includes:
Modifying learning rates, training to test data set ratio, modifying batch size.
What I encountered:
The learning loss is reduced with different activation function (of which I’m not introduced yet).
With more features in, the less it is to adapt to newer data up to a point. Out of 4 examples, some requires a lot more feature than others to easily fit the example well. With the same complex model that do well to an example, given another it works poorly, not at all good.
Reducing the number of feature - less complex do indeed offers more accuracy in a lot of cases.
Some features work well, while other won’t.
The training data is actually a graph of all data that you have - and also test data, given on a graph of coordination. The task here is to allow the behaviors of the prediction and the model to learn pattern. For example, we have 6 features:
- \(x_{1}\)
- \(x_{2}\)
- \(x_{1}^{2}\)
- \(x_{2}^{2}\)
- \(\sin(x_{1})\)
- \(\sin(x_{2})\) What does this means? This means that the behavior of the prediction - or the allowance of the complexity behavior can be changed. In other words - mathematically, it represents the ability to bends the curve of prediction - either super complex or none at all.
A behavior of overfitting and redundant features is observed:
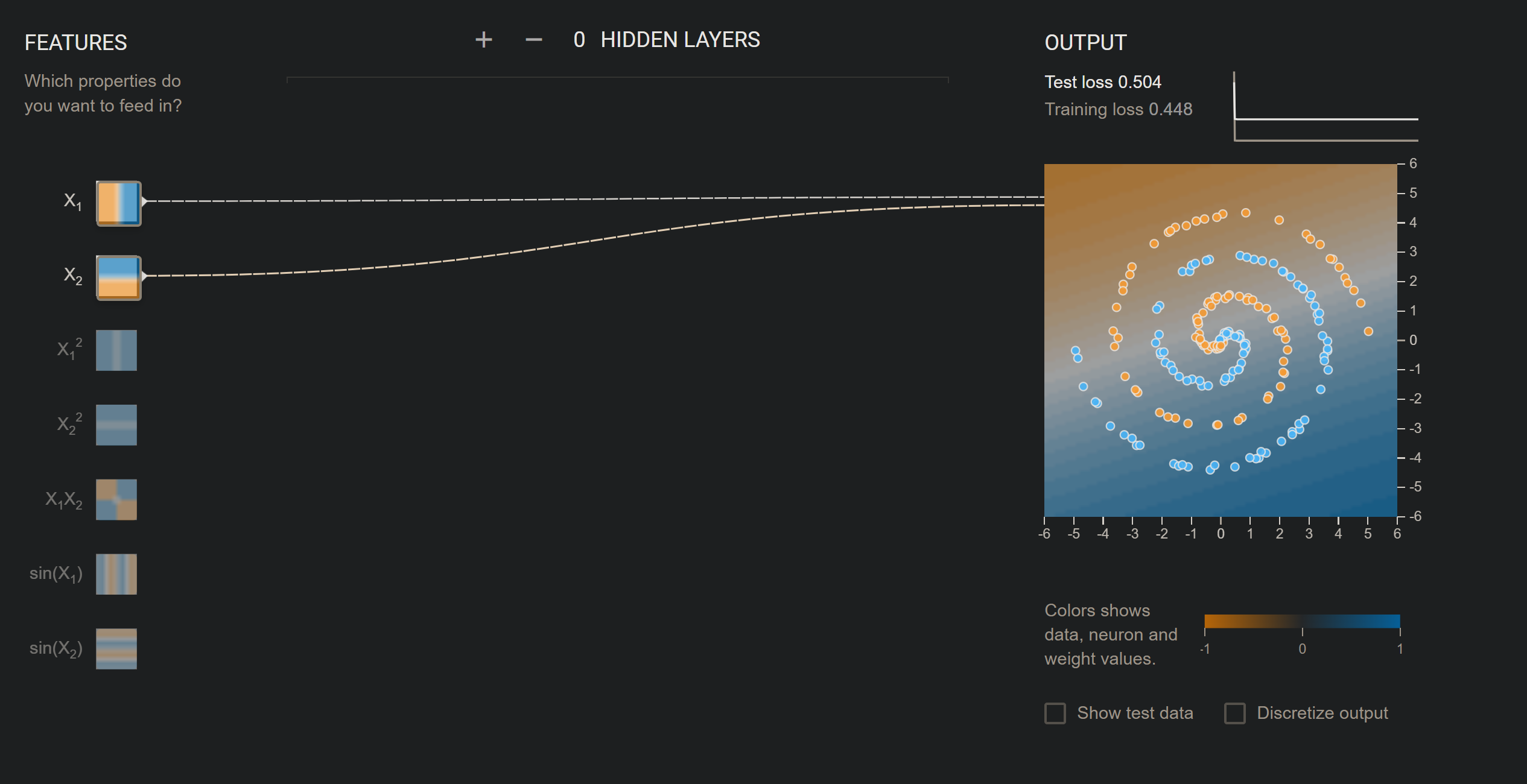 With two simple features, this works well.
With two simple features, this works well. 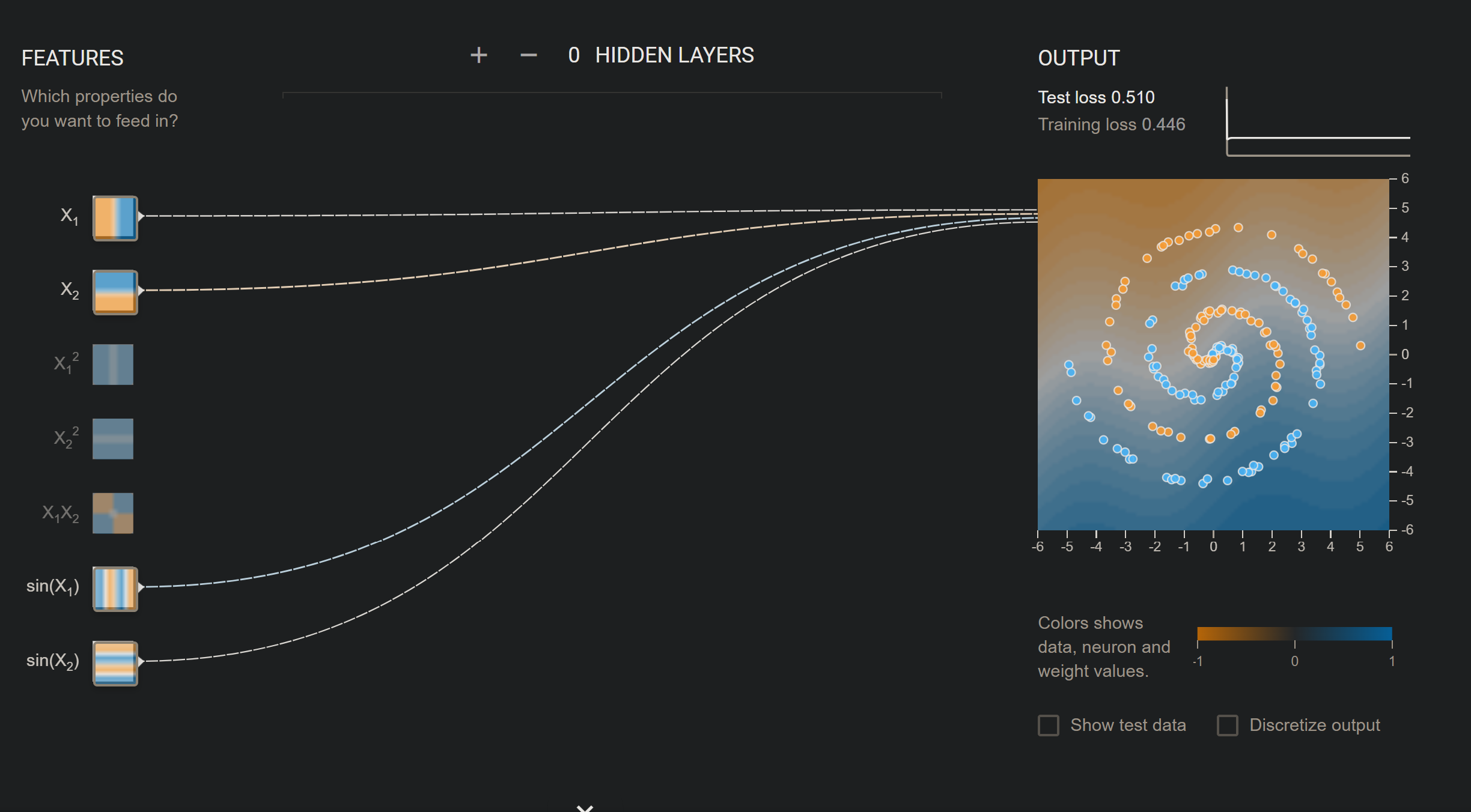 Adding more to the picture, we can still see the change is negligible. But if we try to add \(x_{1}^{2}\):
Adding more to the picture, we can still see the change is negligible. But if we try to add \(x_{1}^{2}\): 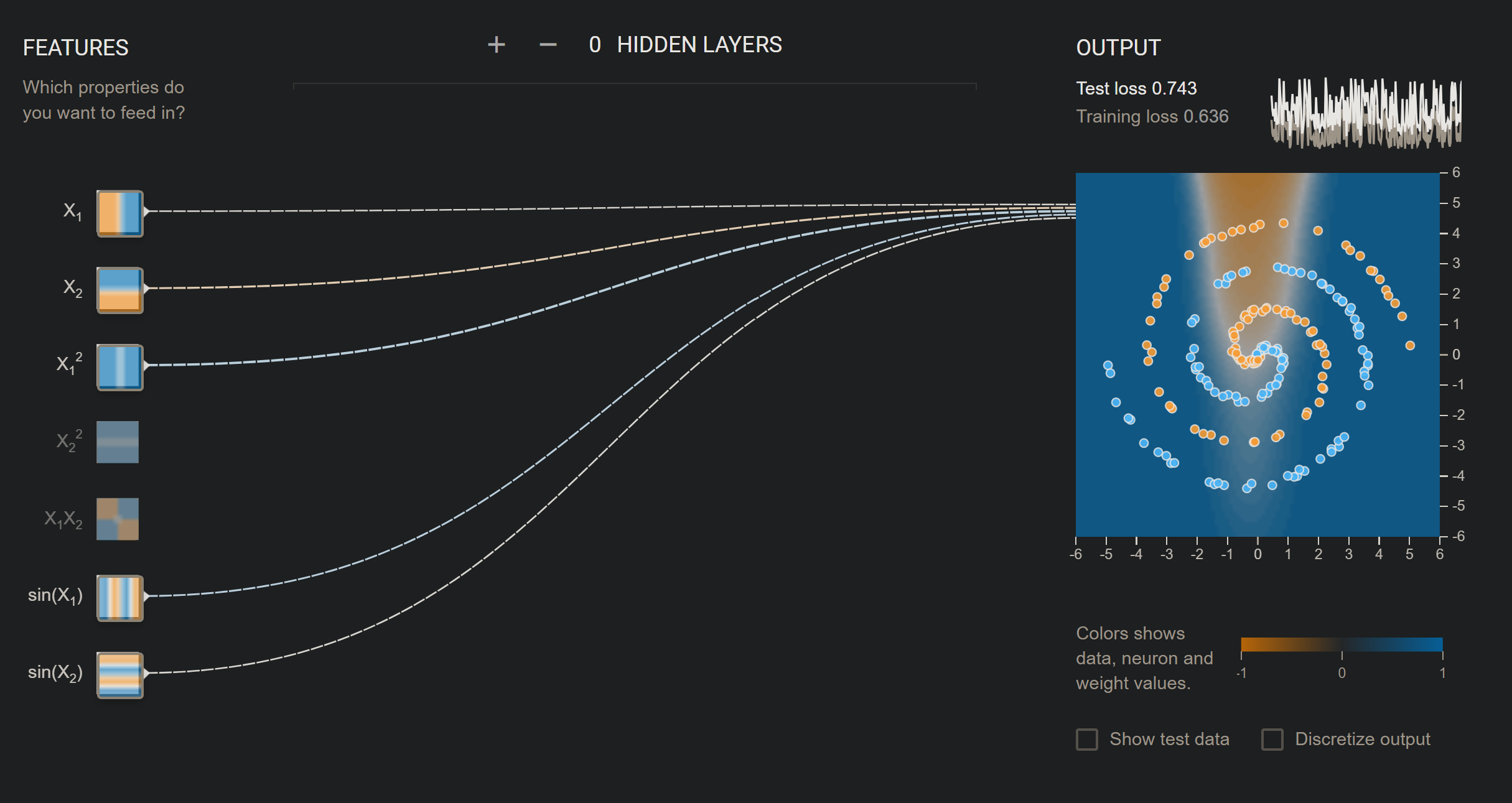 As you can see - some features do not work well with the example - hence more complex it is, sometimes it is very bad for prediction.
As you can see - some features do not work well with the example - hence more complex it is, sometimes it is very bad for prediction.
One thing that I still do not understand is why given complex structure, but a single feature will make it practically… worse. That is, everything works fine even if it is complex, but a single feature will make the whole thing turns into chaos, as you can see from above.
Why this is the case? What is with the behavior?
What indicates complication? - Is \(\sin(x_{1})\) simpler than the behavior of \(x_{1}^{2}\)?