Old notes on overfitting
Overfitting in machine learning, as well as statistic and data science, is when the predicting model is too complex, hence it is inefficient of gaining or adapting to newer data and cases.
Generalization refers to your model’s ability to adapt properly to new, previously unseen data, drawn from the same distribution as the one used to create the model. If the model is overfitting, it is unable to adapt that much, and the same goes for the opposite, which is underfitting.
Generally, we say the model is overfitting if the ratio of \[\frac{\text{complexity of the model}}{\text{training set size}}\] is too high, and underfitting if that is too low.
Let’s take an example.
Suppose you have a situation that the task is to distinguish between sick (blue) and healthy (orange) tree.
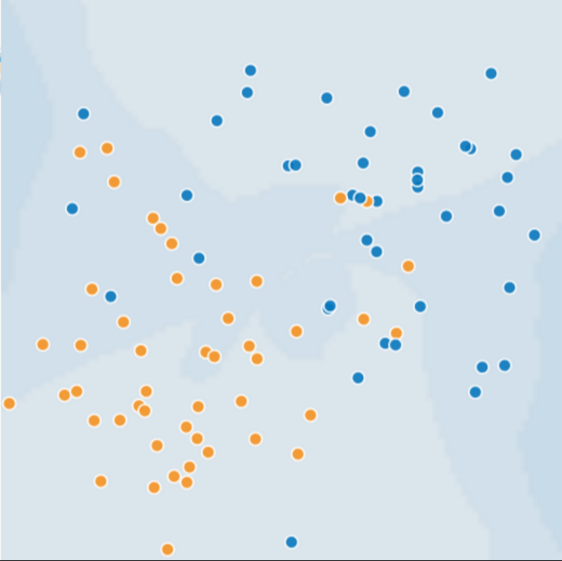
Now, we have a model that can separate quite accurate with low loss:
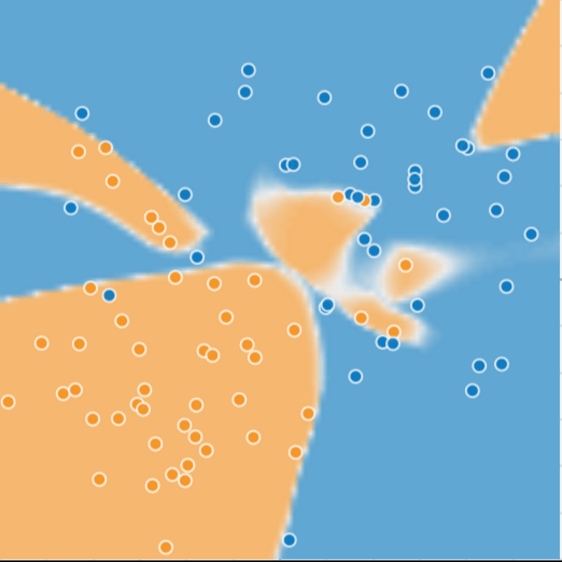
But this is when the data is quite discrete, and have low noise. Now we observe that when adding new data into the pool, the model pretty much adapt poorly to the new data:
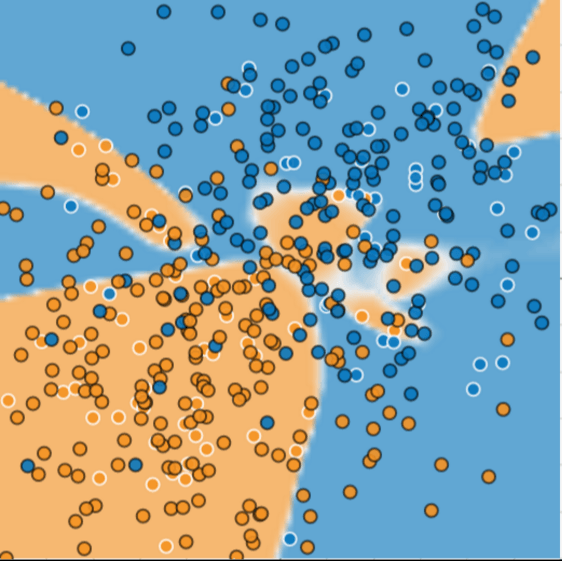
We can see there are many tress left behind, or being mis-categorized. So why this is happening?
The Peril of Overfitting Overfitting, in a nutshell, means take into account too much information from your data and/or prior knowledge, and use it in a model. To make it more straightforward, consider the following example: you’re hired by some scientists to provide them with a model to predict the growth of some kind of plants. The scientists have given you information collected from their work with such plants throughout a whole year, and they shall continuously give you information on the future development of their plantation.
So, you run through the data received, and build up a model out of it. Now suppose that, in your model, you considered just as many characteristics as possible to always find out the exact behavior of the plants you saw in the initial dataset. Now, as the production continues, you’ll always take into account those characteristics, and will produce very fine-grained results. However, if the plantation eventually suffer from some seasonal change, the results you will receive may fit your model in such a way that your predictions will begin to fail (either saying that the growth will slow down, while it shall actually speed up, or the opposite).
Apart from being unable to detect such small variations, and to usually classify your entries incorrectly, the fine-grain on the model, i.e., the great amount of variables, may cause the processing to be too costly. Now, imagine that your data is already complex. Overfitting your model to the data not only will make the classification/evaluation very complex, but will most probably make you error the prediction over the slightest variation you may have on the input.
Essentially:
- We want the balance between fitting the data well and having the model simple as possible.
- Overfitting is the event happens because of the overcomplexity of a model, to a given extend and given training data, that let it be inefficient and poorly adaptable to newer, never-before-seen situations.
- Intuitively, machine learning is the study that conforms and in true realization, of learning from patterns. Because of this, we are finding the probability distribution of specific situations, or different cases of the same problem and have to learn to predict and do the task for all unforeseeable cases. Hence, a training data set is insufficient to prepare for unlimited amount of special, edge cases and others. If the model fits too well, me might conceive this as being unreliable to new data and overall handling.
- Similarly, underfitting - meaning the model does not fit the training data set enough, means the same.
Another example of underfitting and overfitting is shown:
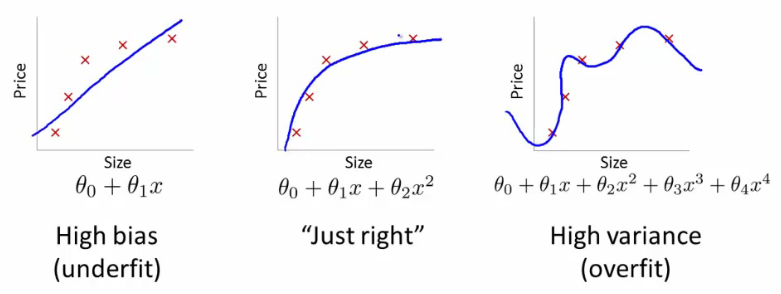
Hence, a principle in machine learning is, the modern of Ockham’s: > Principle of modelling > The less complex an ML model, the more likely that a good empirical result is not just due to the peculiarities of the sample.
In modern day, statistical learning theory is the field that resolves this problem. From this, we concluded of the generalization bounds. Of this bound, we see that the model’s ability to generalize to new data is based on 2 main factors:
\[ \text{Generalizing ability} \longrightarrow \begin{cases} \text{model complexity} \\ \text{training data's performances} \end{cases} \]
To examine and get the model ready for unforeseeable data, we divide the training data into: - Training set: to train the model. - Test set: to test the model.
Intuitively, this is when you learn from school, then doing homework and test.
The ML fine print
In generalization, we have the following assumption:
- Examples are independent and identical from a normal distribution. That means examples do not influence each other, and all of them is to a single situation faced (either finding stuff, or doing something, without any other side purpose that is redundant).
- The distribution is stationary - it does not change with time, that ensure the future is certain of patterns.
- We drew examples from partitions from the same distribution.
In practice, violation exists, often for a specific purpose, and when we violate them, the first step is to always look at the metric. ___
Reference
https://developers.google.com/machine-learning/crash-course/generalization/peril-of-overfitting https://datascience.stackexchange.com/questions/61/why-is-overfitting-bad-in-machine-learning https://www.ibm.com/topics/overfitting