Introduction to AI
The topic has been around ever since the old time, for example Descartes (1637)

Descartes on AI
Pioneers like Marvin Minsky, the godfather of AI, led the world in its shape of AI in the earlier stage of it (1940s-1960s)
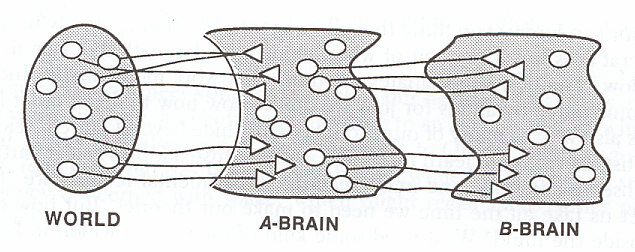
The concept of layering brain - \(A,B,C\)-brain (Marvin Minsky, 1956)
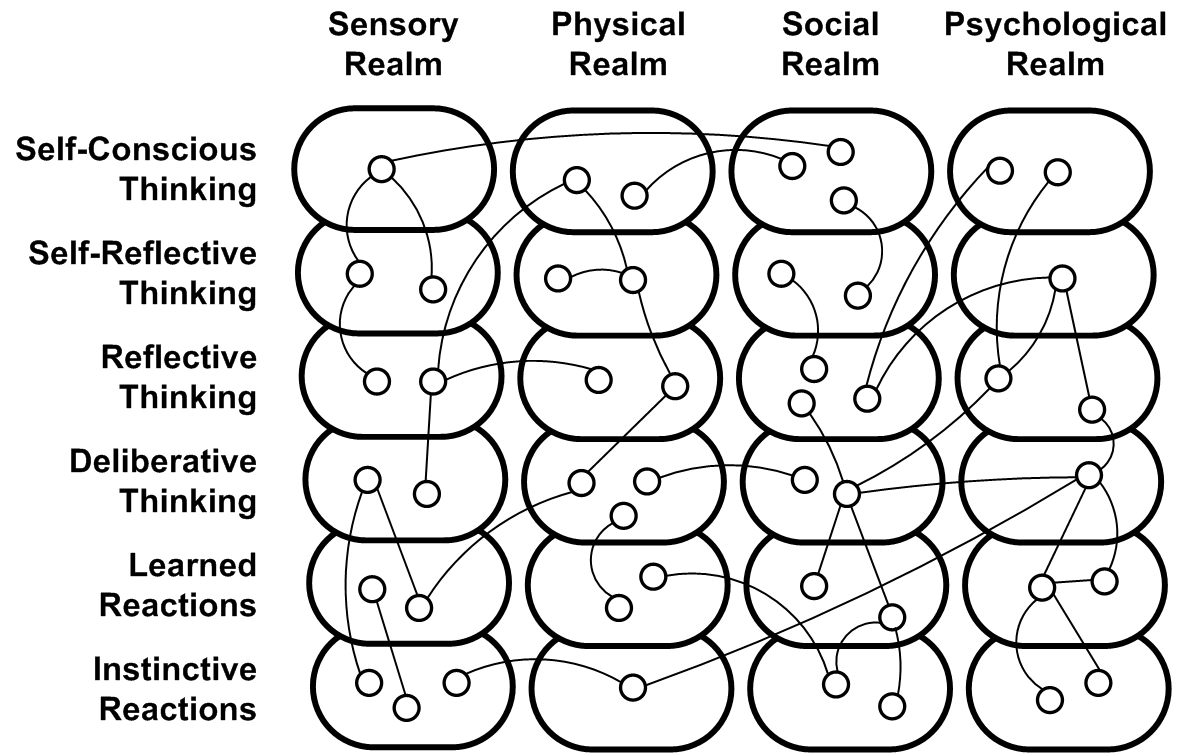
The Society of Mind - according to Marvin Minsky
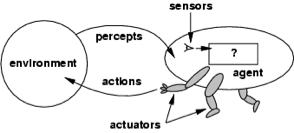
The general concept of artificial intelligence - the agent and the world
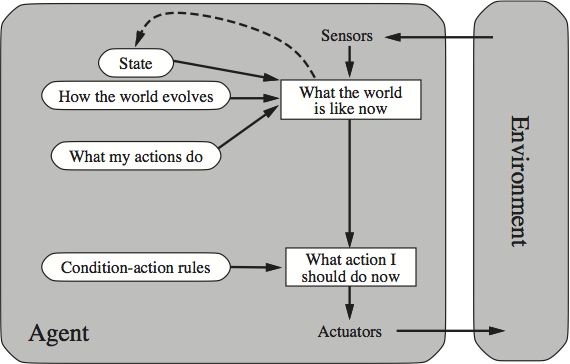
A sophisticated reflex agent
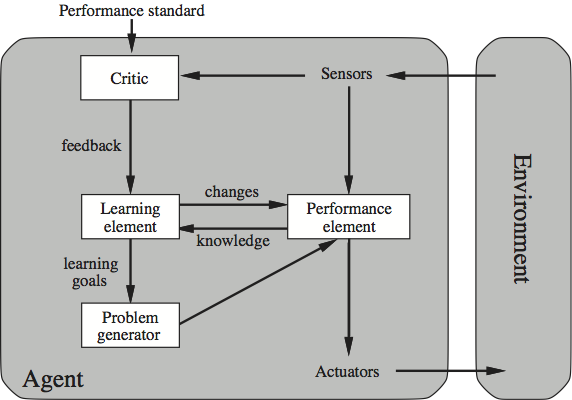
A learning agent
Learning
One of the most important aspect of such model, for any unique application, is to think, and to be able to learn. This is encoded in the theory of machine learning.
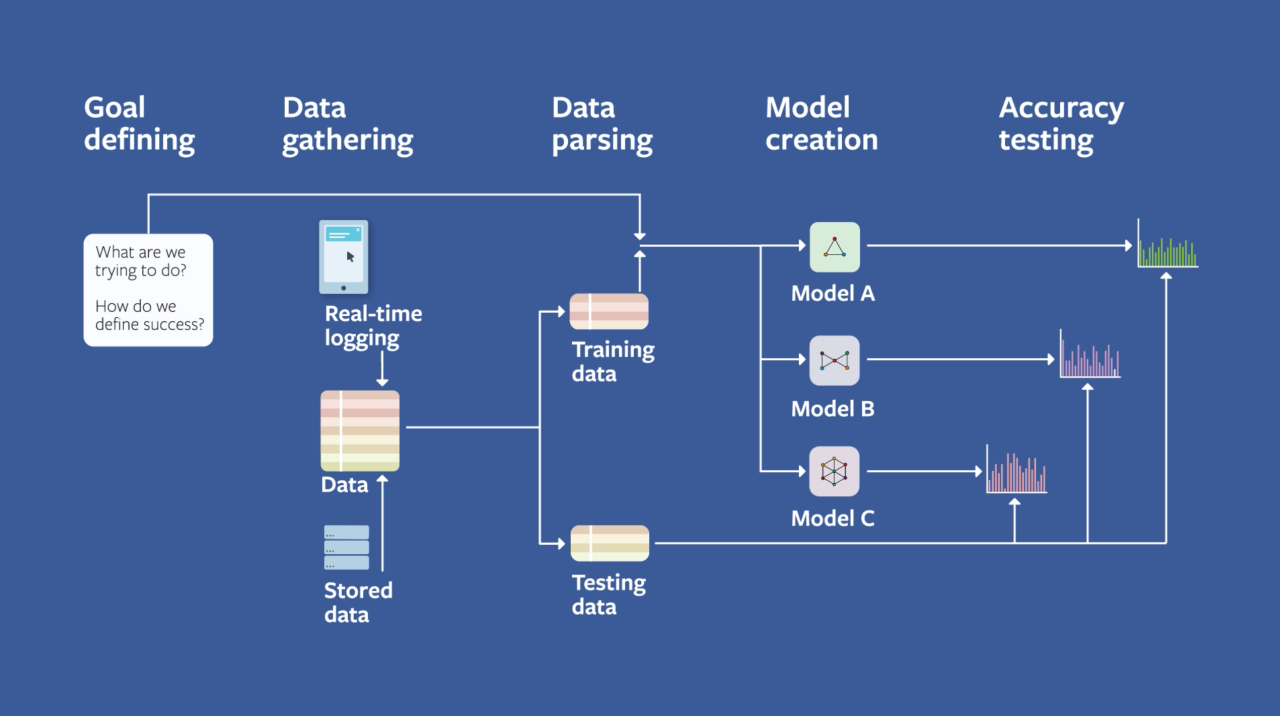
The construct of an ML system
What does that mean? Before machine learning, mathematical modelling is static, and intrinsically rule-heavy.
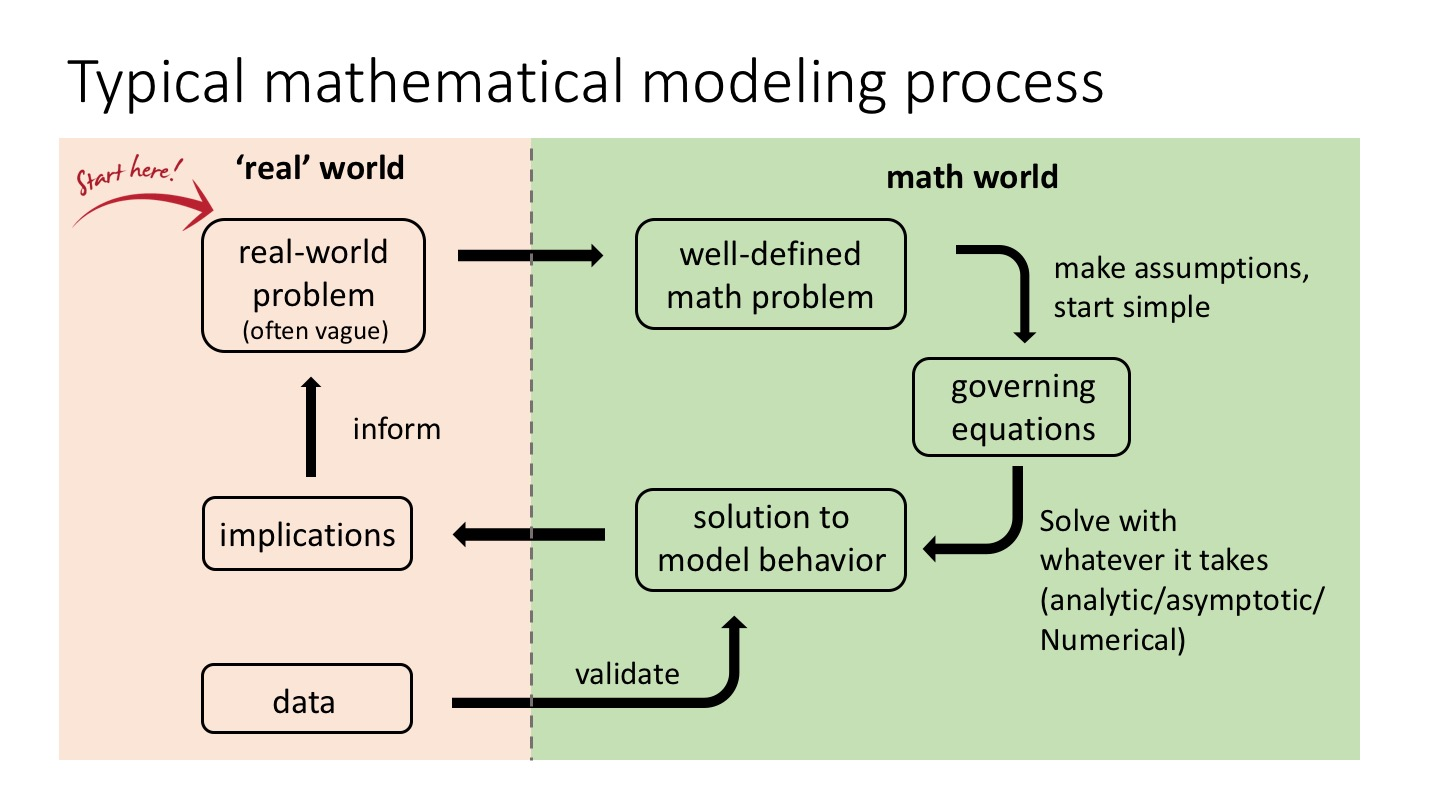
The typical mathematical modelling construct
Supposed the world of population \(p(t)\). Then, \(dp/dt\) is the time-derivative of the population over time. If, we take \(dp/dt=ap\) for arbitrary \(a\in \mathbb{R}\):
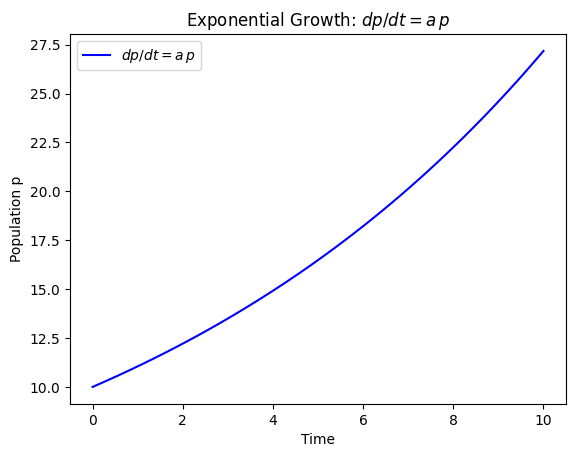
The simple model of growth
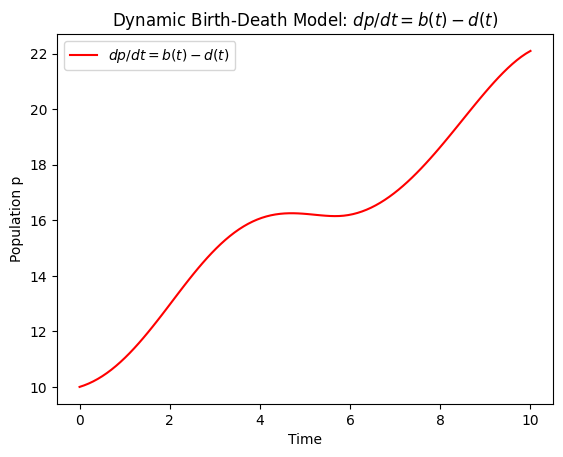
The population, with arbitrary death and birth
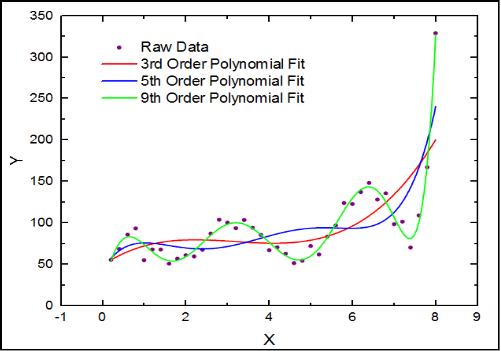
A machine learning model approximating data with the assumption of it being polynomial. Can you do better than it?
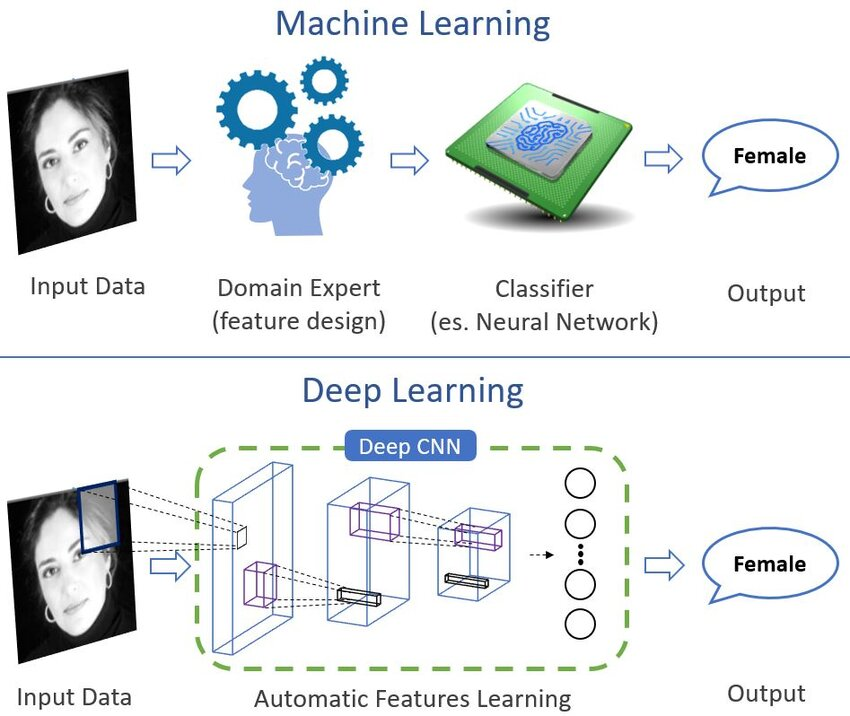
The architypical difference, illustrated of classical and the deep regime of AI
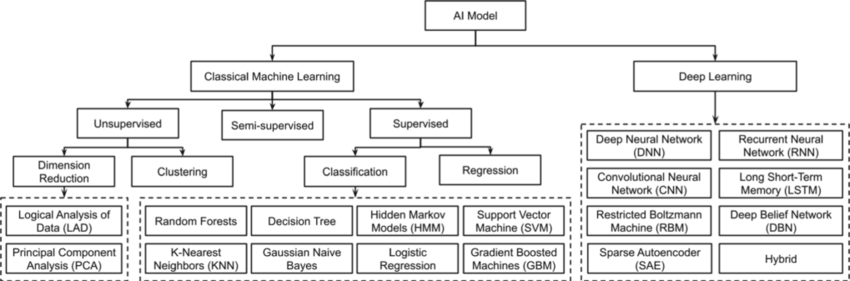
A tree of architectures in classical and neural designs. Note that the neural side, or deep learning, is far cleaner, per usual.
The main general similarity that they exhibit is, however, the reliance on data means they must abide to the concept of train and test partitioning of data. The main reason is that data is generally not perfect.
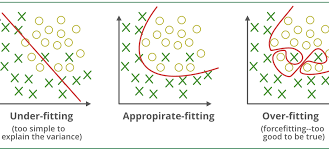
The intuition on generalization
The overfitting concept and resultant in errors, illustrated of the empirical and generalization learning.
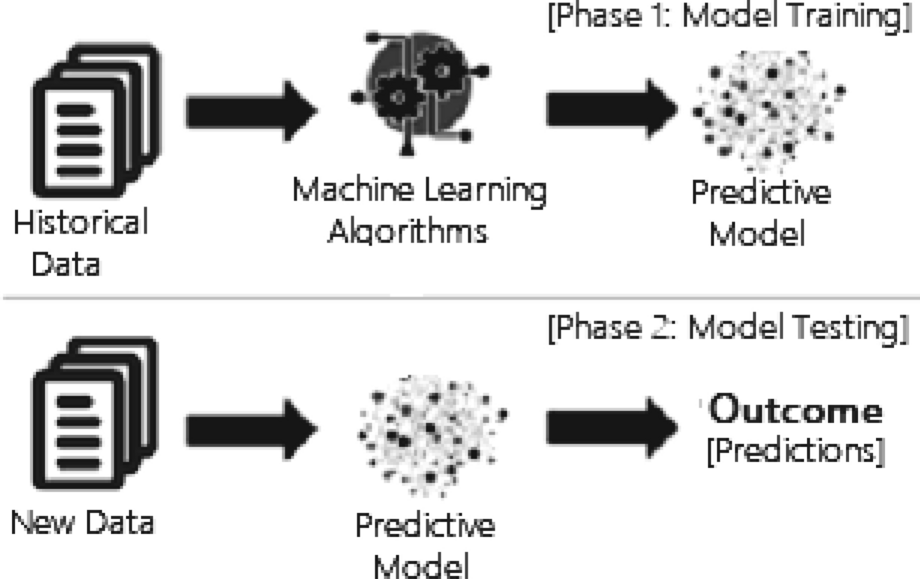
The typical training-testing partition phase of a ML models
More on deep learning
Deep learning, in general, relies on the notion of the neuron \(\mathcal{N}\), which encapsulate the ideal view of a biological neuron.
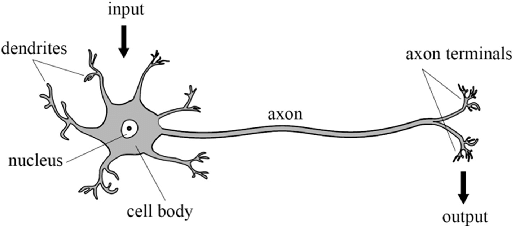
The biological neuron
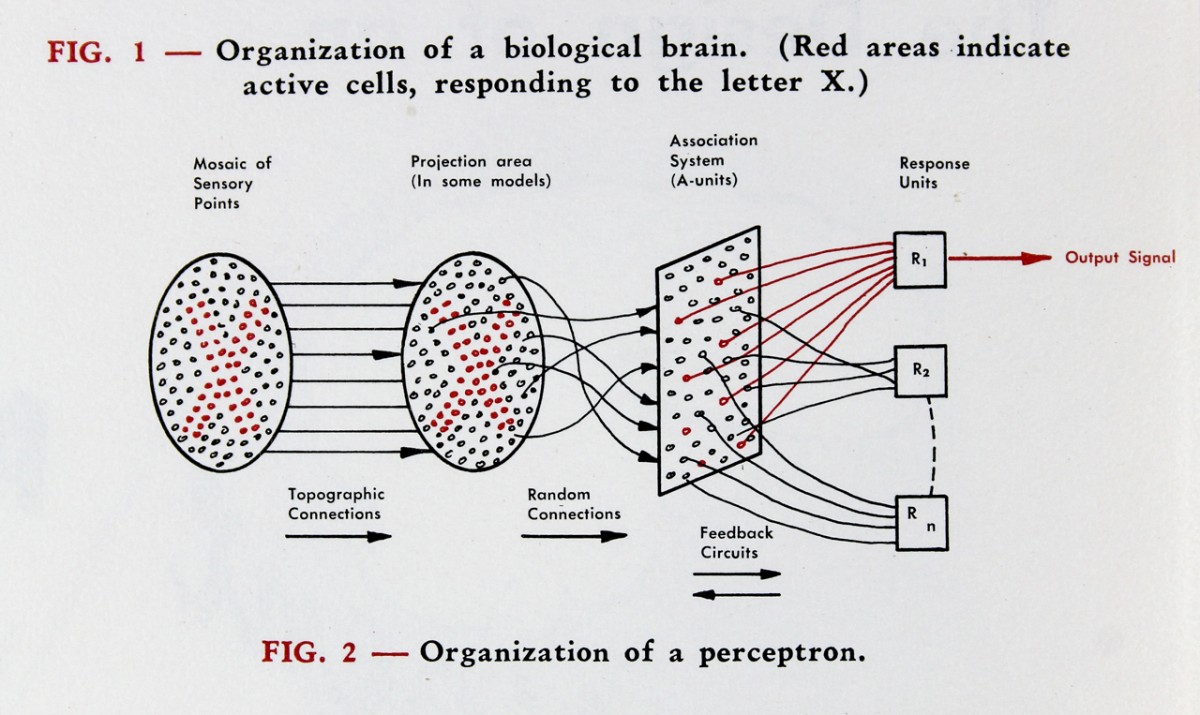
An attempt in the old day, by Rosenblatt (1951)
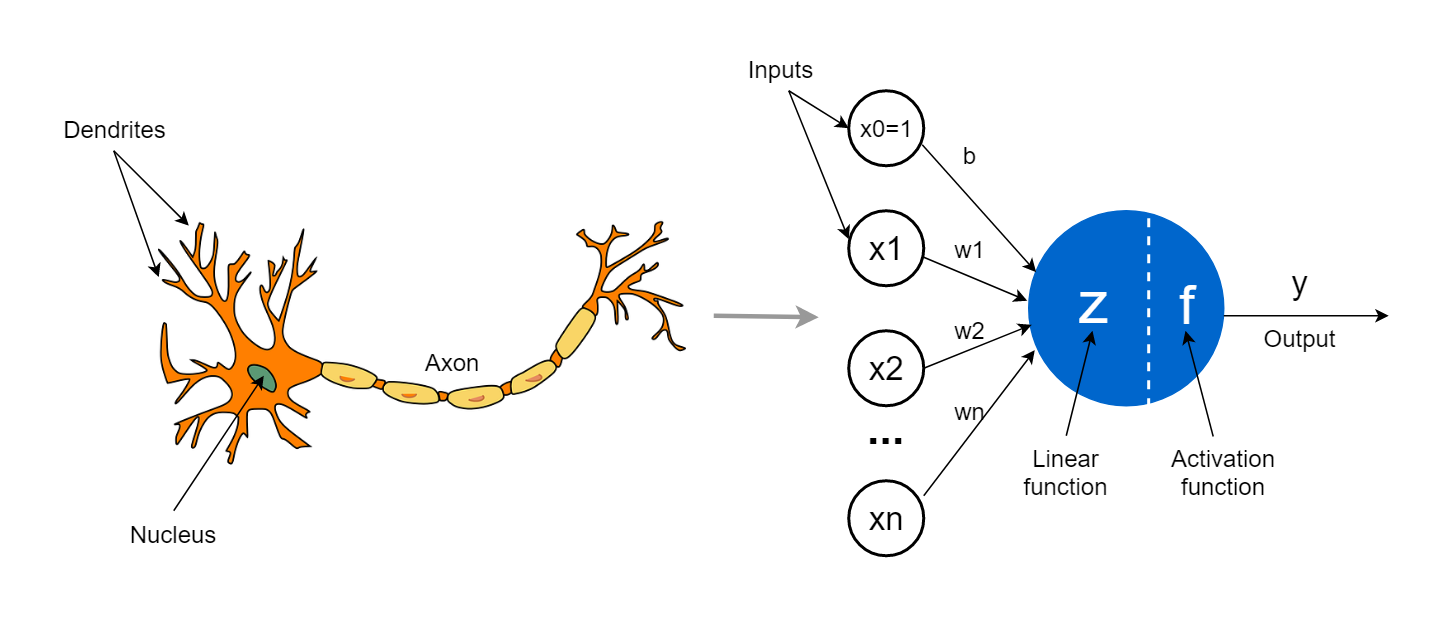
The artificial neuron from its biological counterpart, simplified to computation
Many of such components can be created and conjuncted, into the artificial neural network (ANN).
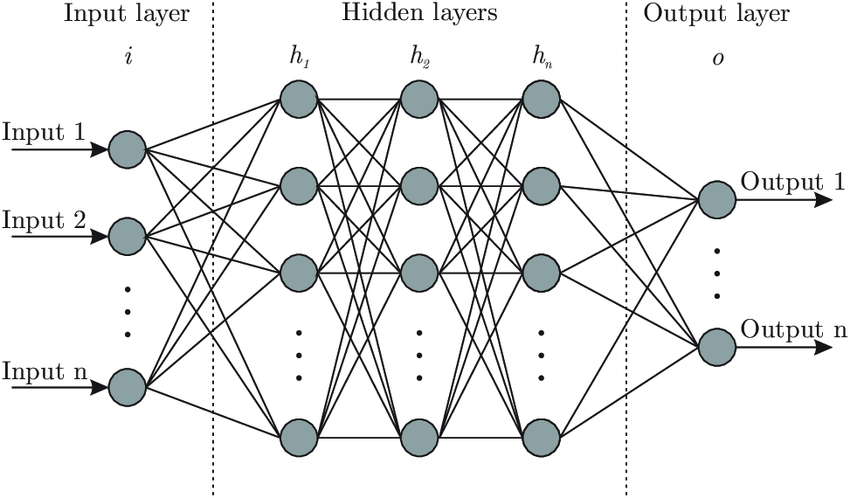
The normal feed-forward, artificial, fully-connected network.
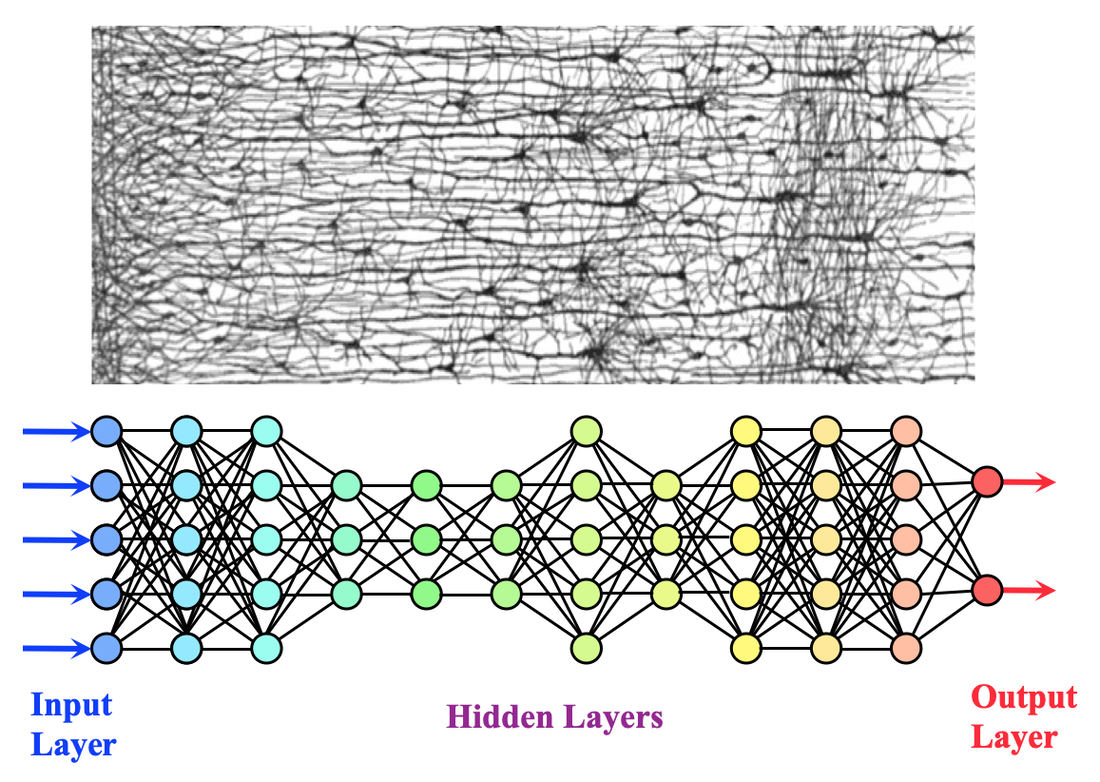
The somewhat replica analysis on deep network and complex neural network in biological brain sections
To train those networks, the technique developed per usual, is the backpropagation technique.
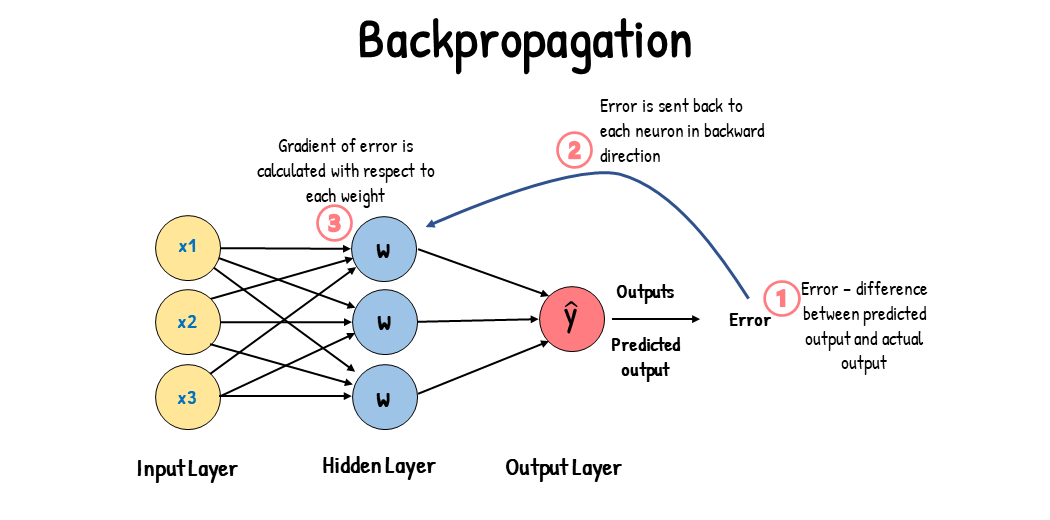
Typical backpropagation on normal network.
For image processing, the most widely use is convolutional neural network (CNN) and their variations
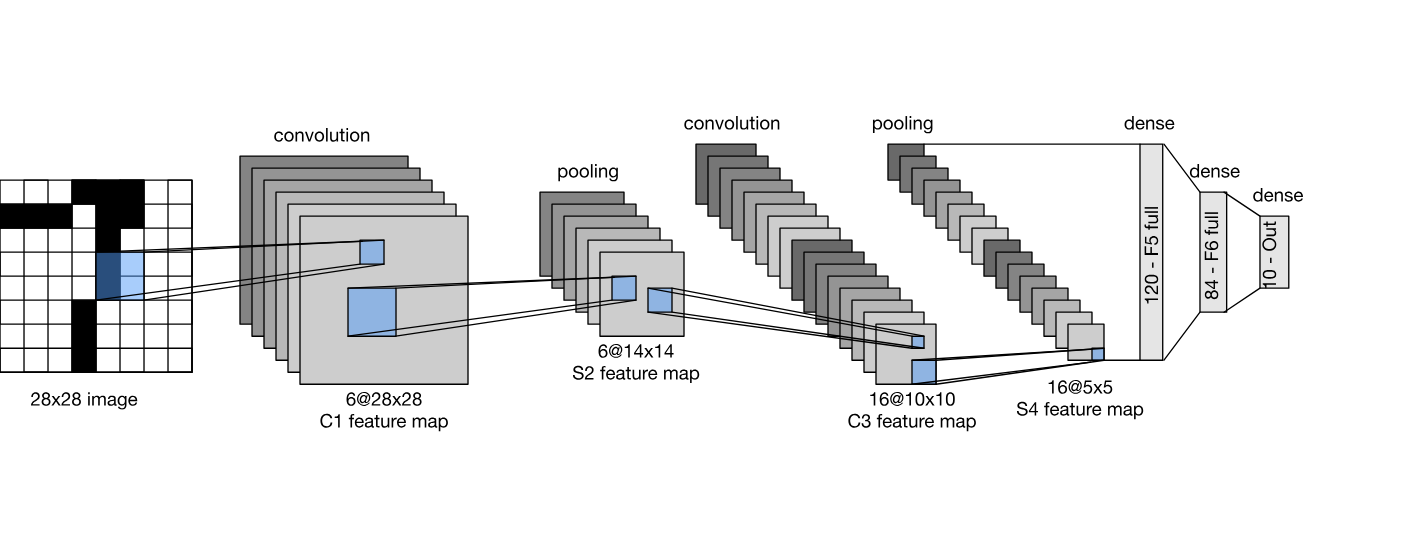
A LeNet, by Yann Le Cun, the first ever convolutional neural network
The main mechanism is focused on the convolutional layer unit, of which compresses information on an image mesh.
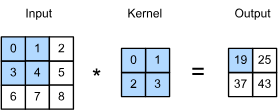
The convolutional layer on a \(3\times 3\) image

Result of CNN with six different channels.
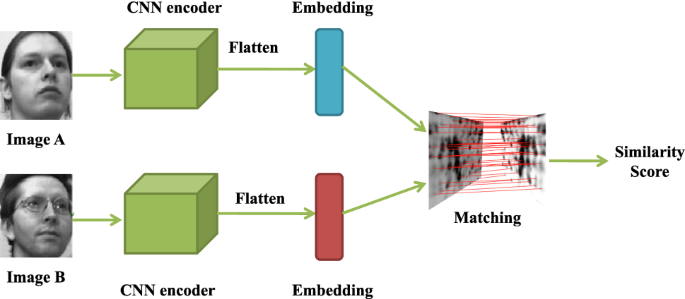
Application of CNN on face matching
In a more modern, requirement of \(1-1\) correspondence between spatial information (since CNN compresses spatial pixel), fully-connected CNN is there to solve such problem.
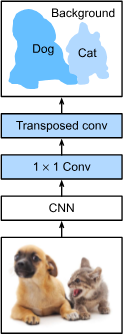
A fully connected convolutional network

Result from FCN on classification. For these test images, we print their cropped areas, prediction results, and ground-truth row by row.
Moving on, if we want the network to facilitate memory, such idea can be done using Recurrent Neural Network (RNN)
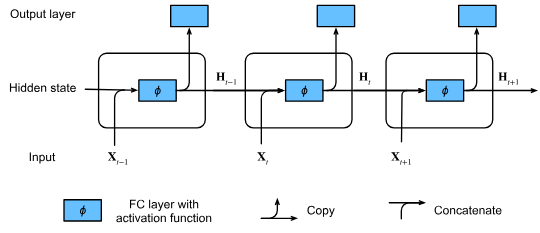
RNN with hidden states
They are mostly used in language processing:
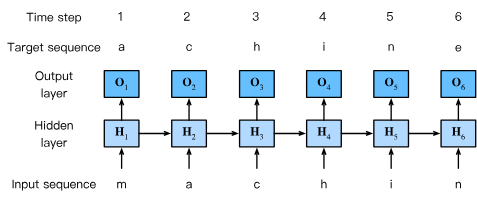
A recurrent network for word processing.
Long Short-Term Memory (LSTM)
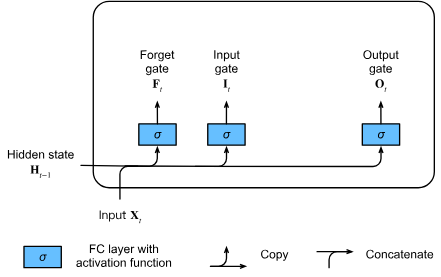
Gated memory cell
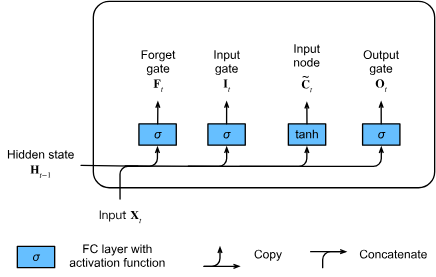
Partially incorporated gated LSTM structure
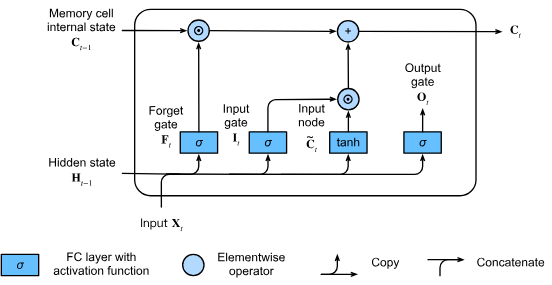
Memory cell incorporation
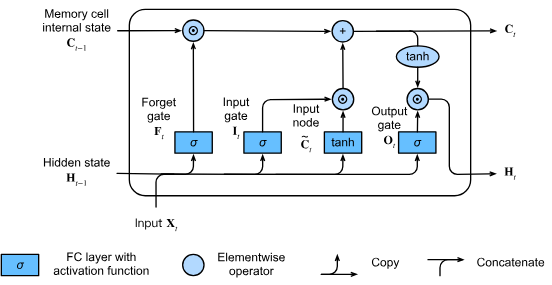
Hidden state incorporation into LSTM
Gated Recurrent Unit (GRU)
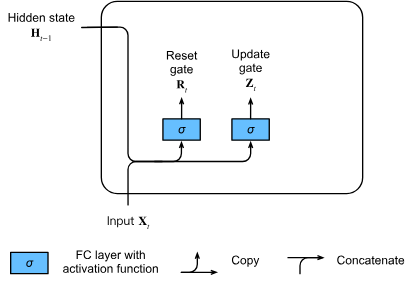
Illustrative GRU reset-update mechanism
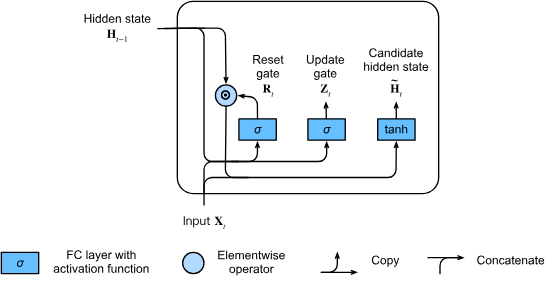
The concept of candidate state addition for main flow of GRU.
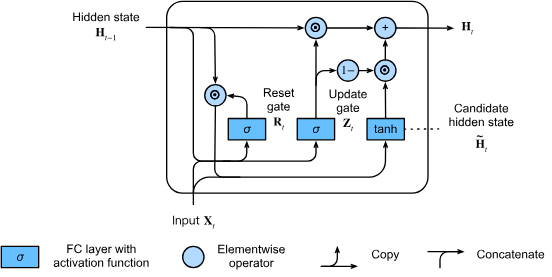
Hidden state addition into GRU, finalizing it.
Attention networks (Transformer architecture)
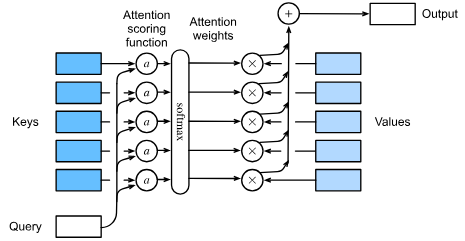
An attention layer form
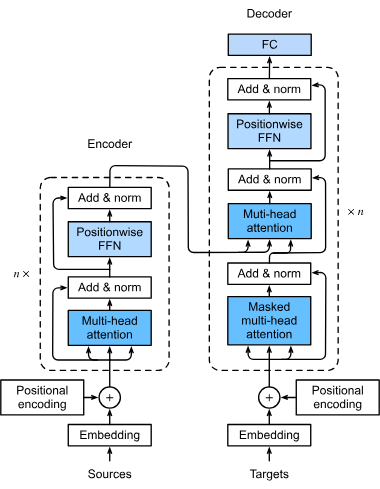
A structure of Transformer architecture
It can also be incorporated into computer vision:
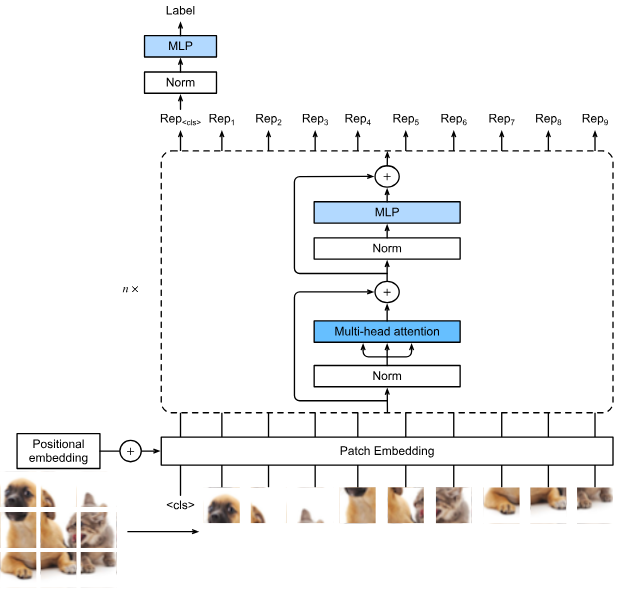
Computer vision plus Transformer.
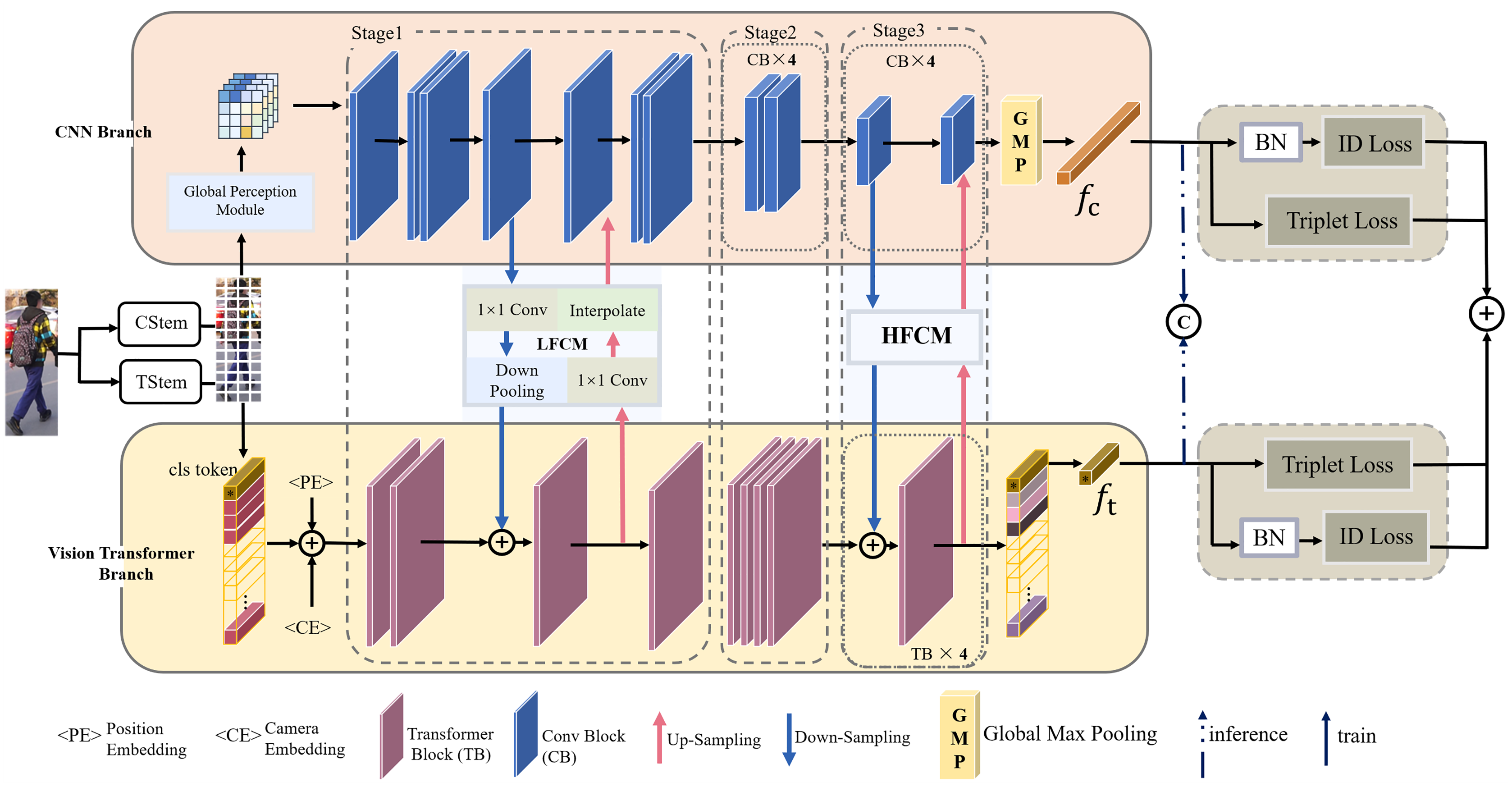
Alternative, parallel CNN-Transformer hybrid
Transfer learning
Usually, structures increase exponentially of the computational cost. We can then use transfer learning for it.
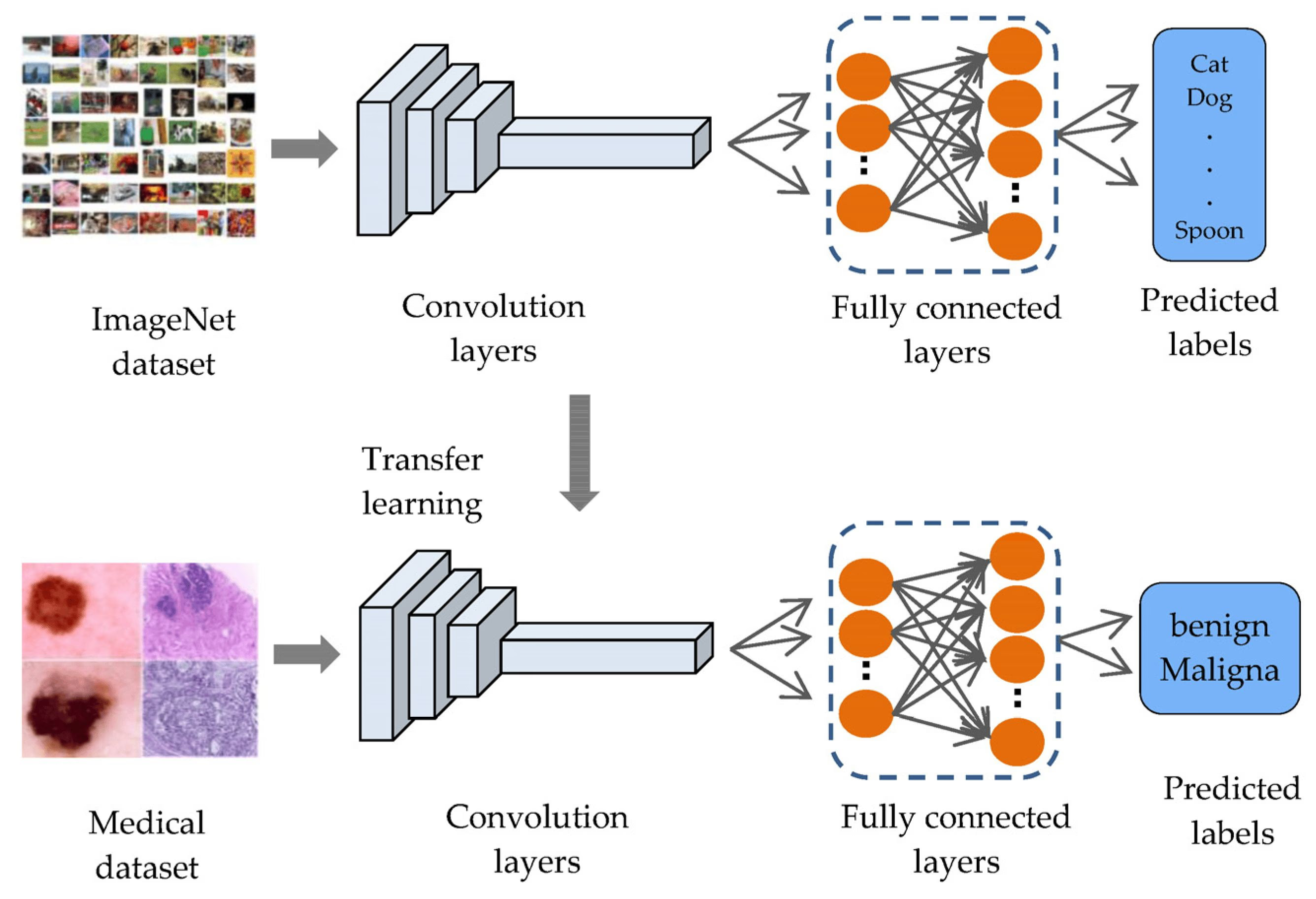
The transfer learning (TL) approach.
The stack includes pre-training, and fine-tuning, both of which serves different scalability criteria
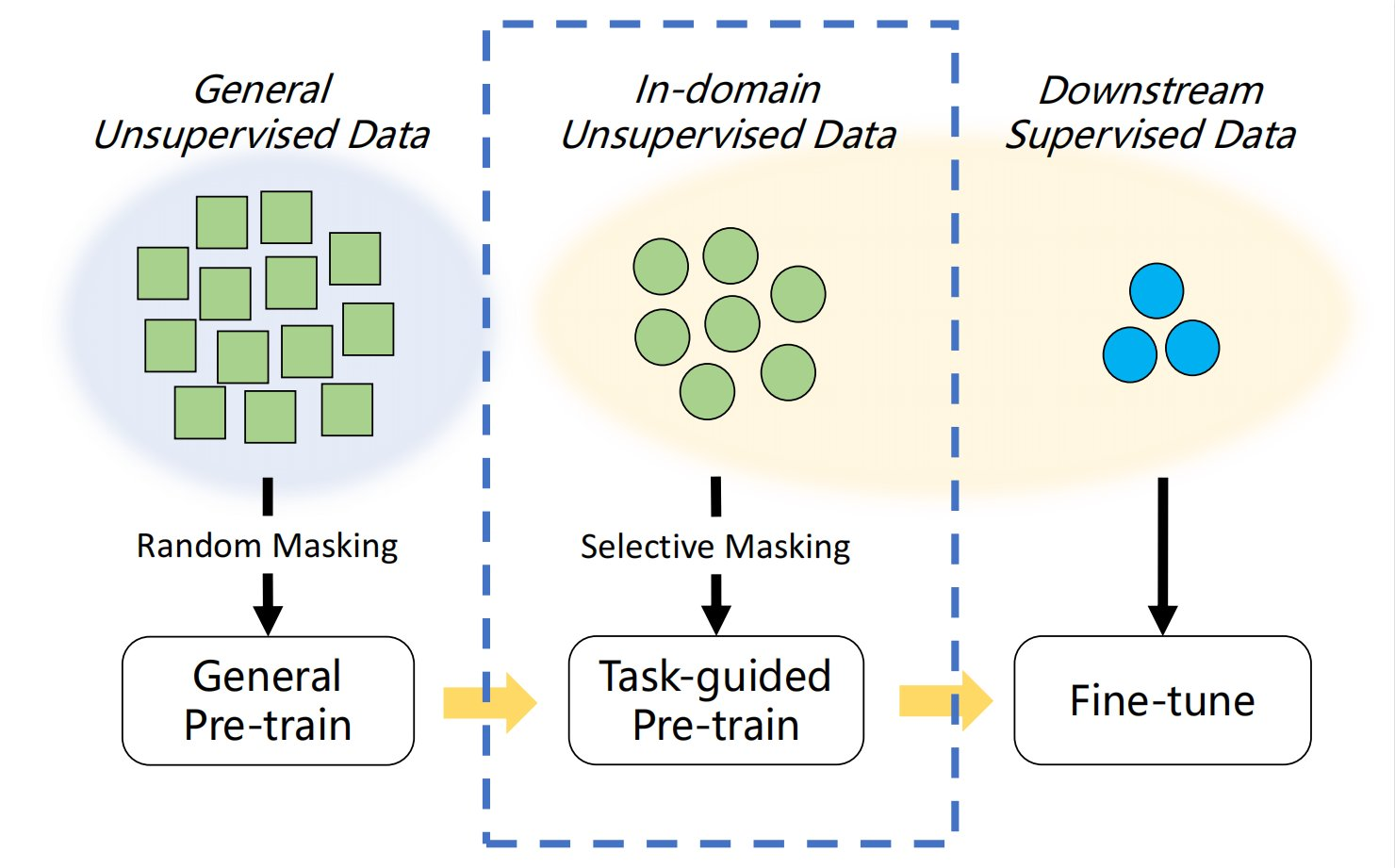
The pre-training and finetuning methods
Generative adversarial network (GAN)
GAN is introduced to back-forth verification between two status - the model and its adversarial misinformation form.
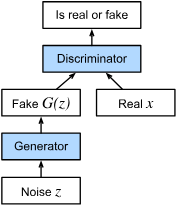
GAN architectural consideration.
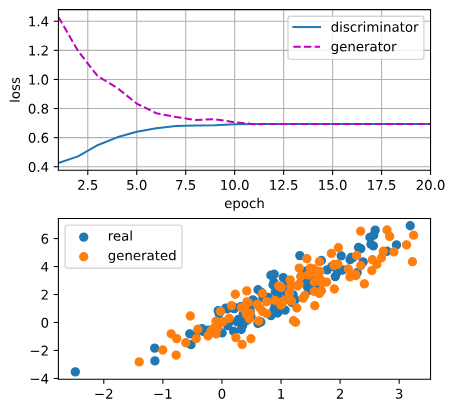
GAN result from discriminator and generator